

首先我们从宏观的视角来窥视下大数据技术框架:
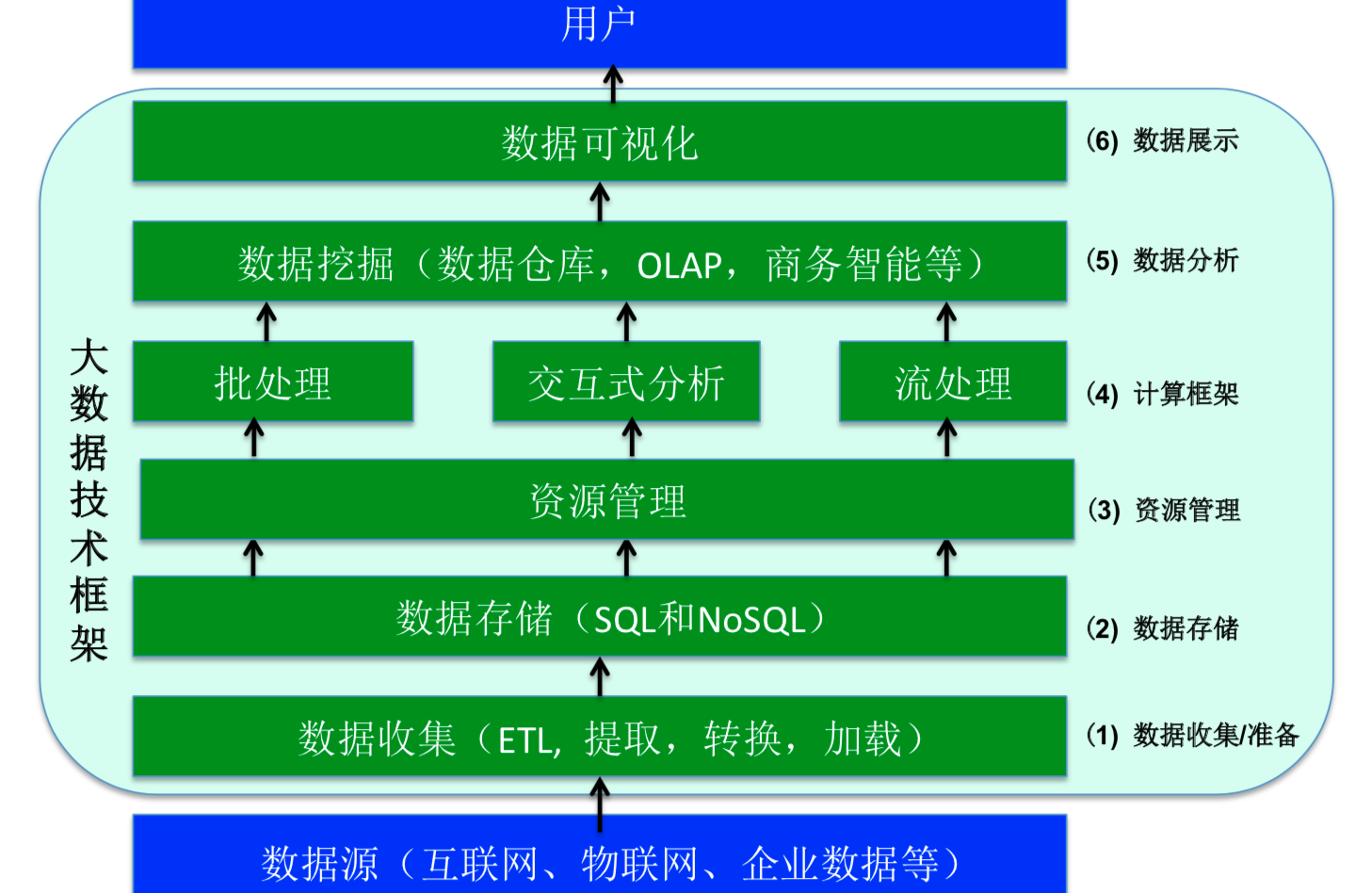
图1 大数据技术框架
从图1可以看出,数据源-数据收集-数据存储-资源管理,这是我们进行数据分析和处理的基本;图中的计算框架包括批处理、交互式分析和流处理:
不同的计算框架的实时性要求是逐渐增强的,spark在整个大数据技术框架中属于第4层计算框架,spark能很好地满足这三种计算要求,这也是spark这么火的原因之一;对数据进行计算后,我们便可以对数据进行分析,训练机器学习模型等;将数据分析或训练得到的结果可视化并展示给用户或者提供一些智能服务,从而获取商业价值。
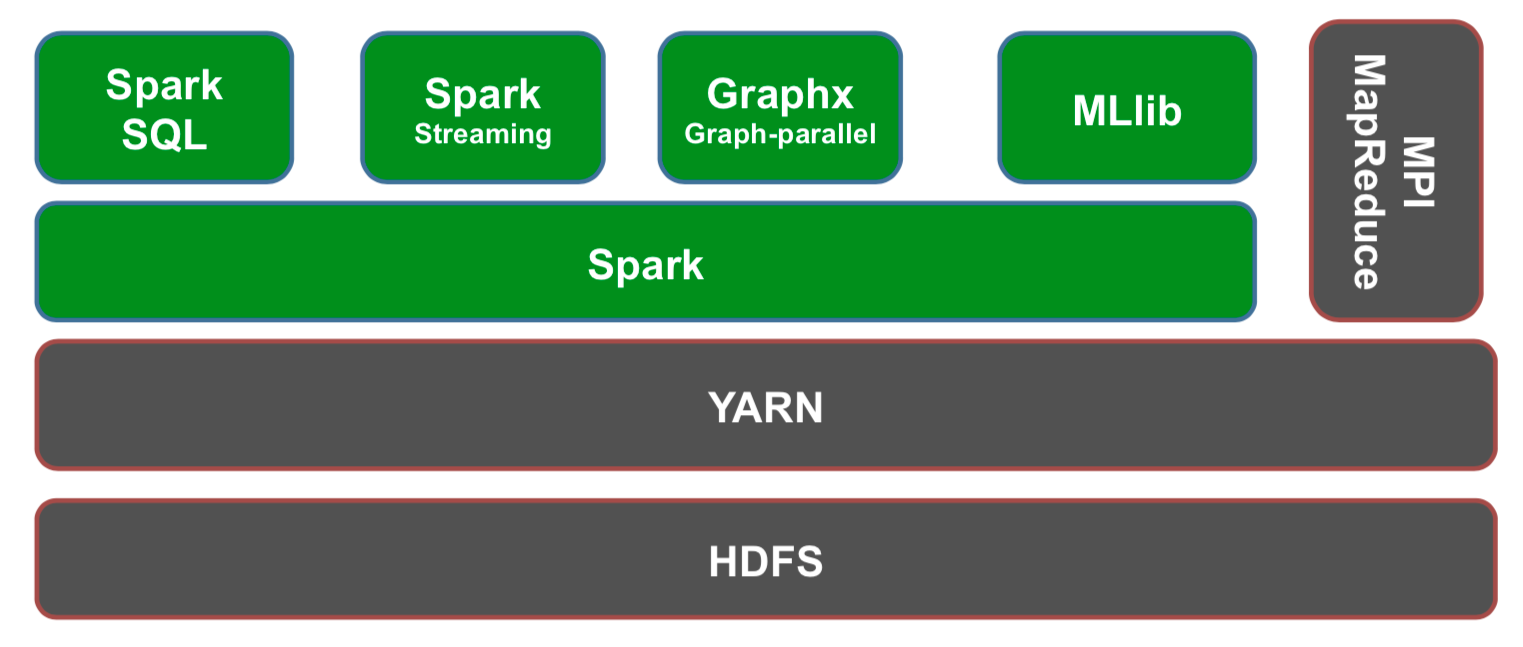
图2 spark 生态系统
spark数据一般放在分布式存储系统里,比如HDFS、Hbase
HDFS的基本原理是将文件切分成等大的数据块(block,默认128MB),存储到多台机器上,这是一个容量巨大、具有高容错性的磁盘。通常的架构是一个NameNode(存放元数据)多个DataNode,为了防止namenode宕机,有一个备用的NameNode:Standby NameNode。
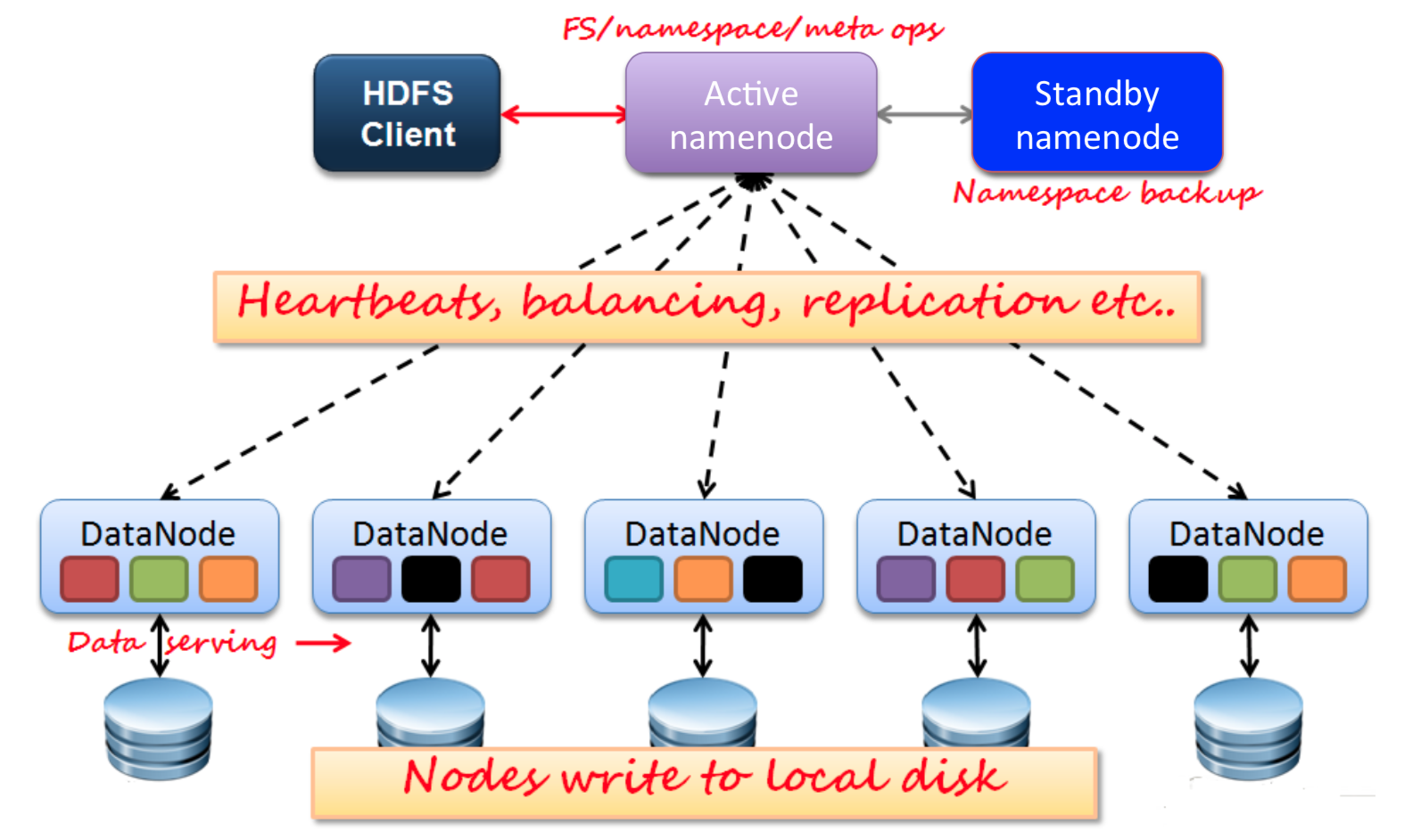
图3 HDFS架构
spark的资管管理与调度使用YARN,spark可以运行在YARN之上,YARN可以对多种类型的应用程序进行统一管理和调度,spark四个主要模块:spark SQL,Spark Streaming,Graphx Graph-parallel,MLlib。
spark的出现时为了解决MapReduce框架的局限性,但并不是在任何情况下,spark都比MapReduce高效。
而且大数据计算框架多样,各自为战:
而spark可同时进行批处理、流 式计算、交互式计算,减少了使用者的学习成本。
RDD:Resilient Distributed Datasets,弹性分布式数据集,与Java里的集合类似,但它多了两个前缀修饰词:分布式、弹性
分布式:用户看到的是一个RDD集合,但是后台是分布在集群中不同的只读对象集合(由多个Partition构成)
弹性:数据可以存储在磁盘或内存中(多种存储级别)
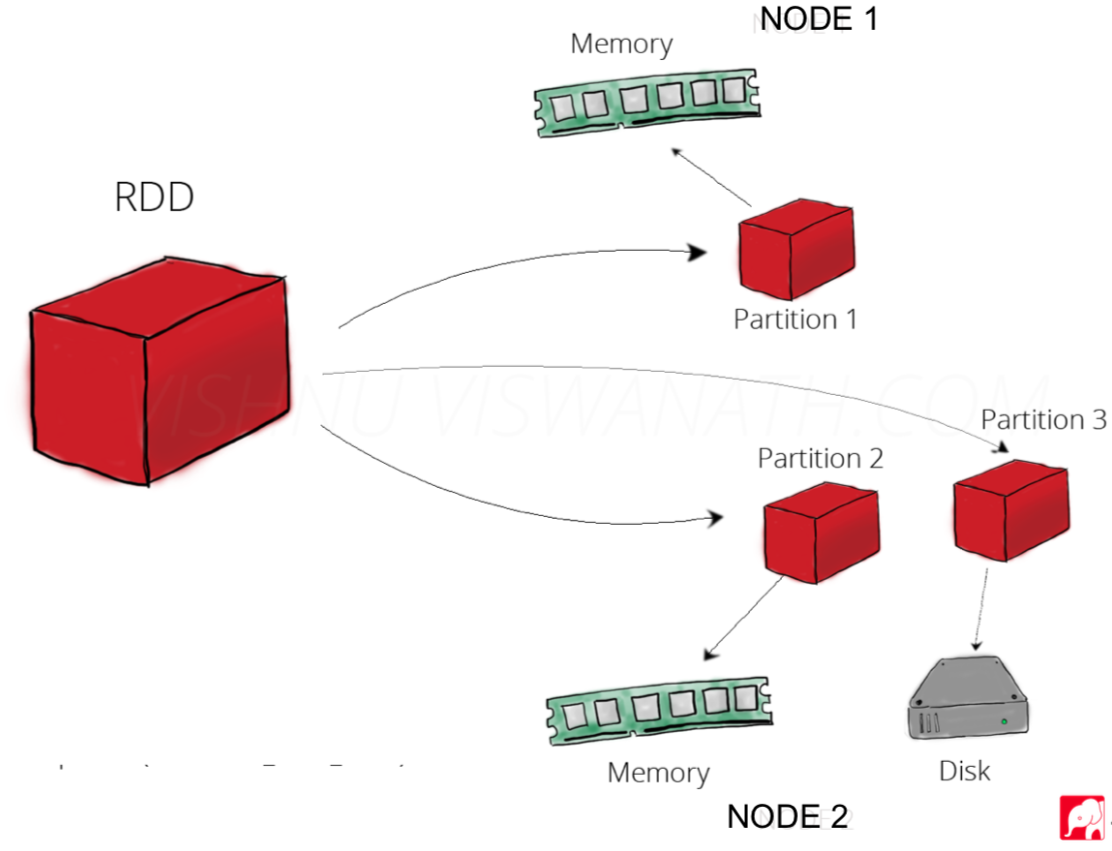
图4 RDD
RDD的两类基本操作:Transformation和Action
Transformation:通过Scala集合或者Hadoop数据集构造一个新的RDD,通过已有的RDD产生新的RDD,比如:map, filter,groupBy,reduceBy。Transformation是惰性执行的,即只会记录RDD转化关系,并不会触发实际计算,知道遇到一个action才会触发。
Action:通过RDD计算得到一个或者一组值,比如:count,reduce,saveAsTextFile。Action会触发程序分布式执行
https://img.mukewang.com/5bc2fc4d00013e9709520848.png
图5 RDD 惰性执⾏行
Spark RDD Cache
通过上面我们可以知道,spark的主要特点:高效是由于使用了Cache机制来进行迭代计算,同时RDD的弹性也是因为数据可选择是存放在内存还是磁盘中,spark RDD cache允许将RDD缓存到内存中或磁盘上,以便于重用:
val data = sc.textFile(“hdfs://nn:8020/input”)
data.cache() //实际上是data.persist(StorageLevel.MEMORY_ONLY)
//data.persist(StorageLevel.DISK_ONLY_2)
我们来分析下一个spark程序的架构,每一个程序的main函数运行起来都由两类组件构成:Driver和Executor,main函数运行在Driver中,一个Driver可以转化为多个Task,每个Task都可被调度运行在指定的Executor中。
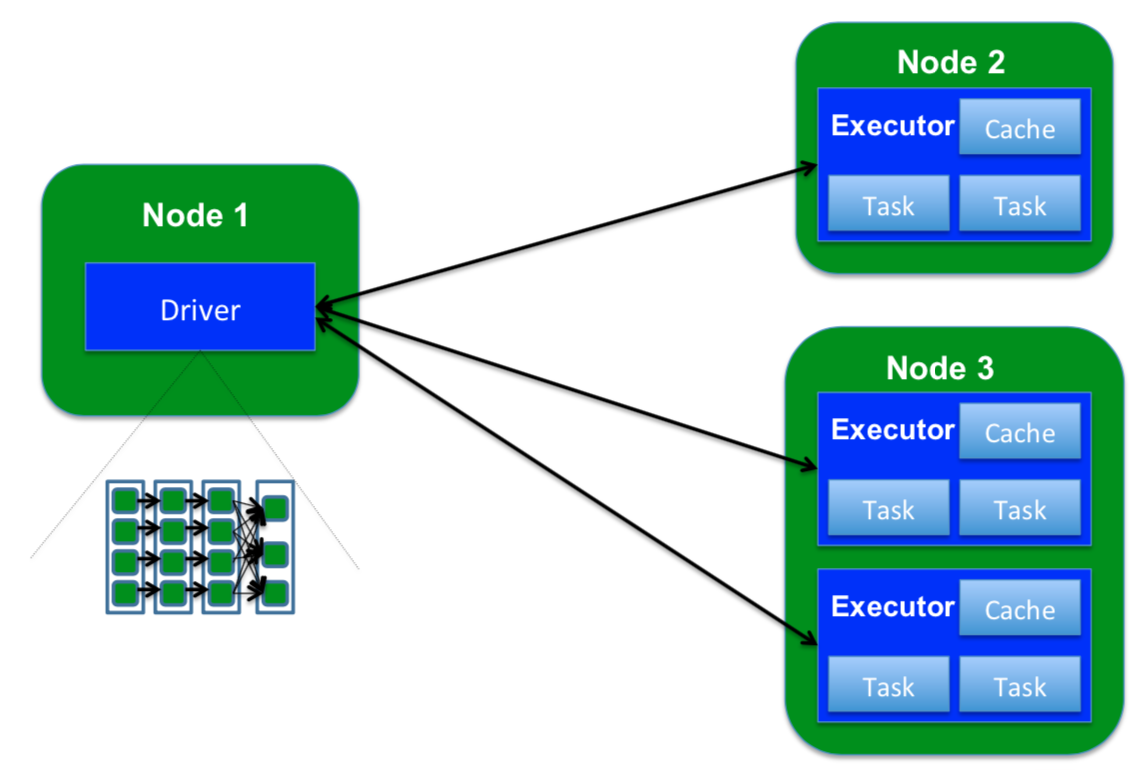
图6 spark 程序架构
spark的运行模式有三种,可以在$SPARK_HOME/conf/spark-defaults.conf中使用spark.master来指定:
yarn-client内部处理逻辑
yarn-client模式下,Driver是运行在Client上的,spark程序是在哪台机器上提交的,这个Driver就运行在哪台机器上,也就是main函数运行在哪台机器上,当提交你的程序到yarn上时,背后发生了什么?
假设现在有四个服务器组成的yarn集群,一个为Resource Manager,其余三个为Node Manager,当Node Manager启动的时候会将Node Manager上的信息注册到Resource Manager中,在本地部署好hadoop环境之后即可提交spark程序(1),Resource Manager会启动一个Node Manager(2);再由Node Manager来启动你的Application Master(3);Application Master需要的资源是由你运行的程序所指定的,Application Master启动后会与Resource Manager通信,为executor申请资源(4),如果一个executor挂了,Application Master会重新向Resource Manager申请一个executor并启动在某个Node Manager上,那么如果是Node Manager挂了,Application Master会向Resource Manager申请相同数量的executor并启动;executor拥有资源后,Application Master会与Node Manager通信来启动executor(5、6),每个executor与在客户端Client上的Driver通信领取task(虚线部分)
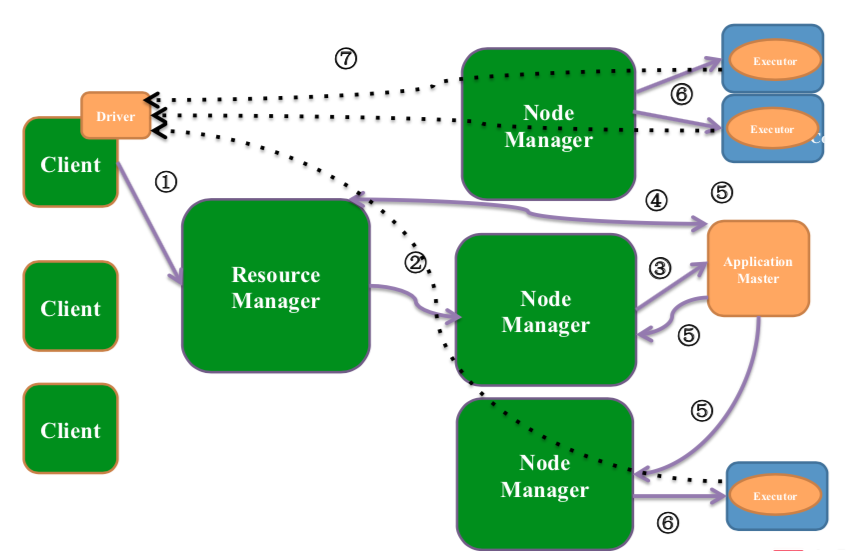
图7 程序运行模式:YARN分布式模式(yarn-client)
Resource Manager:一个中心的管理服务,决定了哪些应用可以启动executor进程,以及何时何地启动
Node Manager:一个在每个节点运行的从服务,真正执行启动executor进程,同时监控进程是否存活以及资源消耗情况
Application Master:在 YARN 中,每个应用都有一个 Application master 进程,这是启动应用的第一个容器。这个进程负责向 ResourceManager 请求资源,当资源分配完成之后,向 NodeManager 发送启动容器的指令。
推荐几个不错的博客论坛